When solving a machine learning problem we follow a consistent series of sets.
First, partitioning the data set into training and test sets using the train_test_split function. Then fitting the model with the training set.
And finally, applying the model on the test set to evaluate the trained model's performance.Let's recall the reason why to divide the original data into training and test sets. The test set is a way to estimate how well the model trained on the training data would perform on the new previously
unseen data. The test must have same general attributes as the original data set.
Understanding Cross Validation
Cross-validation is a way to predict the fit of a model to a hypothetical validation set when an explicit validation set is not available.
This is a method that goes beyond evaluating a single model using a single Train/Test split of the data.
We may have noticed that when choosing different values for the random state seed parameter in the train_test_split function, that the accuracy score we get from running a classifier can vary quite a bit just by chance depending on the specific samples that happen to end up in the training set.
Cross-validation runs multiple different training test splits and then averaging the results which gives more stable and reliable estimates of how the classifiers likely to perform.
The figure below shows how Cross-validation works on the data.The most common type of cross-validation is k-fold cross-validation most commonly with K set to 5 or 10.
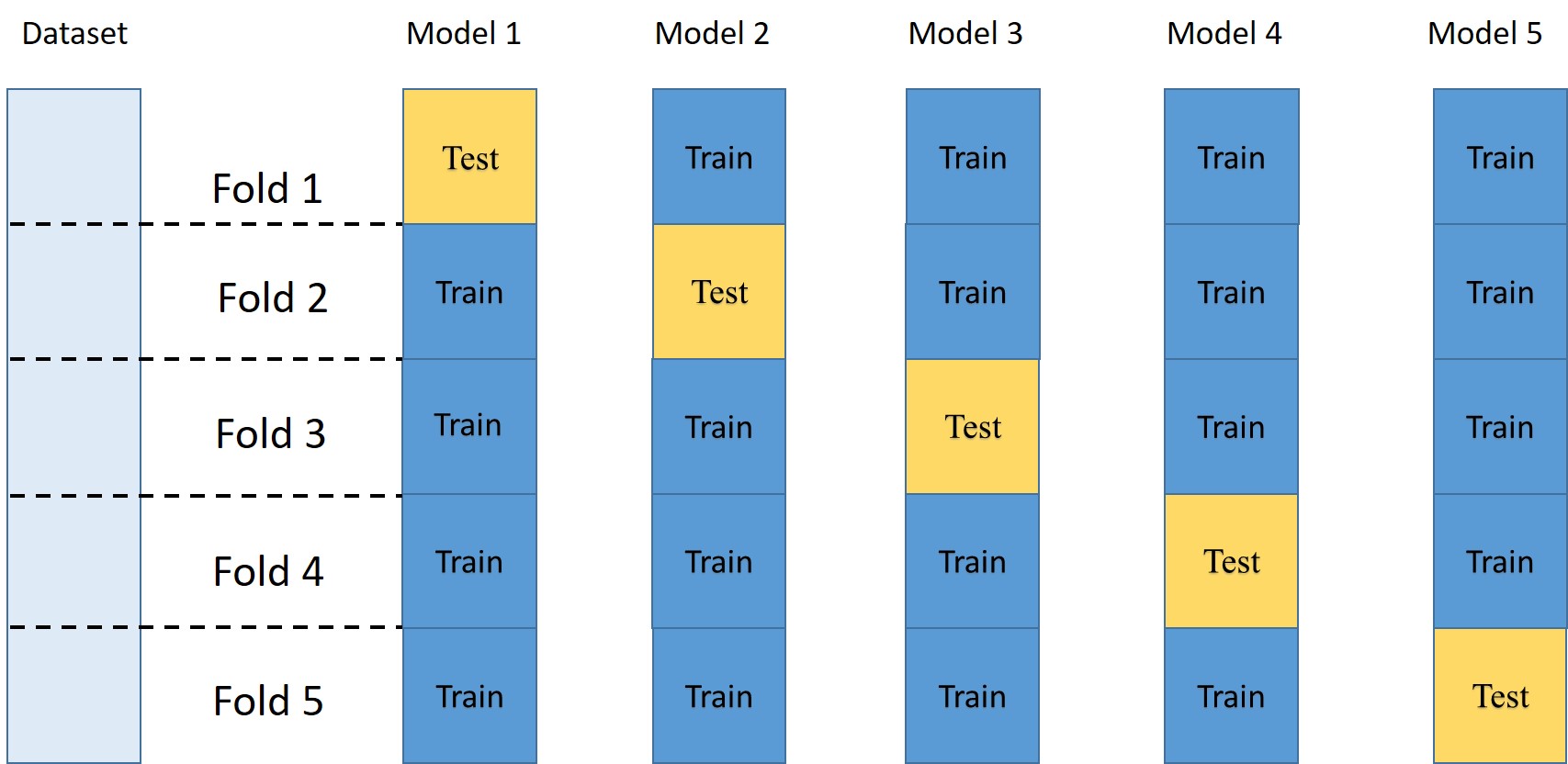
Let's take an example of five-fold cross-validation, the original dataset is ramdomly partitioned into five parts or close to equal size. Each of these parts is called a "fold". Then a total of five models are trained. The first model Model 1, is trained using folds 2 through 5 as the training set and tested using fold 1 as test set. The second model Model 2, is trained using Folds 1, 3, 4, and 5 as the training set, leaving Fold 2 as test set for evaluation , and so on. When all five models have five accuracy values, the values are averaged to find the model accuracy.
In scikit-learn, we can use the cross_val_score function from the model selection module to do cross-validation. The parameters for this function are: the model we want to evaluate, and then the data set , and then the corresponding target values. By default, cross_val_score does threefold cross-validation. So it returns three accuracy scores, one for each of the three folds. In order to change the number of folds, we can set the CV parameter. For example, CV equals 5 will perform five-fold cross-validation. Then we compute the mean of all the accuracy scores across the folds and report the mean cross-validation score as a measure of how accurate we can expect the model to be on average. One benefit of computing the accuracy of a model on multiple splits instead of a single split, is that it gives us potentially useful information about how sensitive the model is to the nature of the specific training set.
It does take more time and computation to do cross-validation.
So for example, if we perform k-fold cross-validation and we don't compute the fold results in parallel,
it'll take about k times as long to get the accuracy scores as it would with just one Train/Test split.
However, the gain in our knowledge of how the model is likely to perform on future data is usually well worth this cost
Stratified Cross-validation
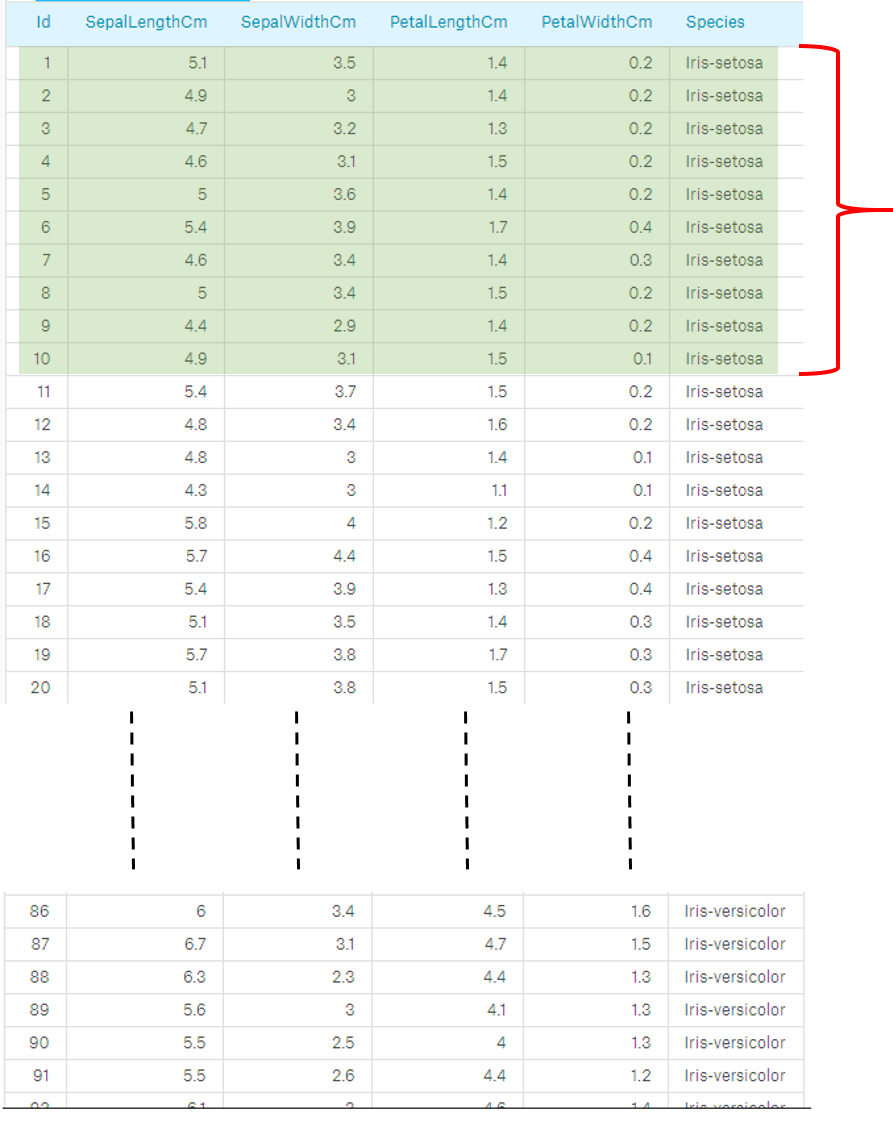
Some problems can exhibit a large imbalance in the distribution of the target classes: for instance there could be several times more negative samples Dataset sometimes might have been created in such a way that the records are sorted or show bias in ordering by class label. For example, if a dataset contains same target label (class) in fold 1 and missing other target labels or classes which is our test set to evaluate our Model. So problems of imbalance in distribution may reduce the informativeness of the evaluation.
In the example below, we can see that in fold 1 only Iris-setosa class is considered.Therefore
In such cases Stratified Cross-validation is used to ensure that relative class frequencies is approximately preserved in each train and validation fold.
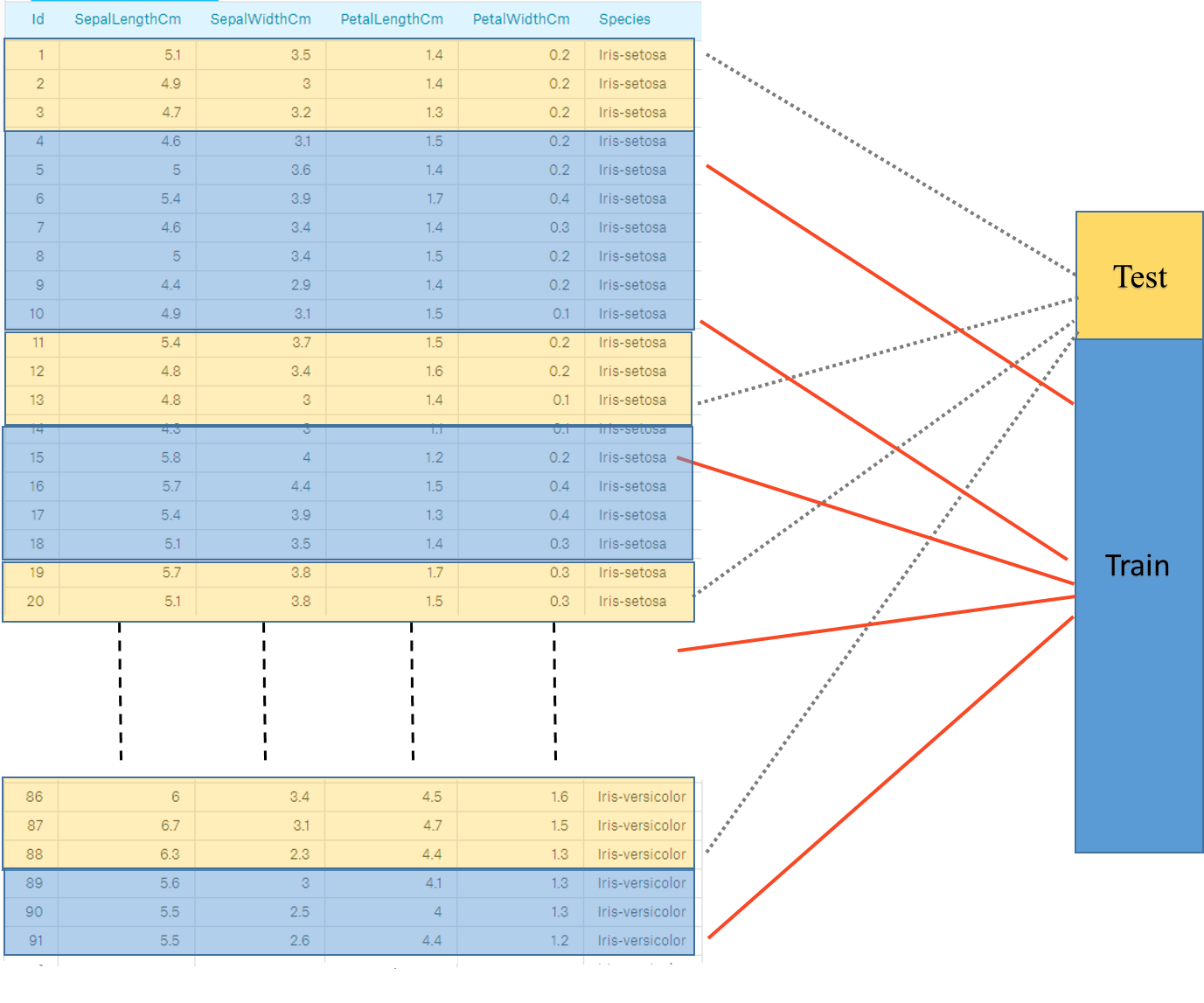
In Stratified Cross-validation, each fold contains a proportion of classes that matches overall dataset. This helps to represent all classes fairly in the test set.
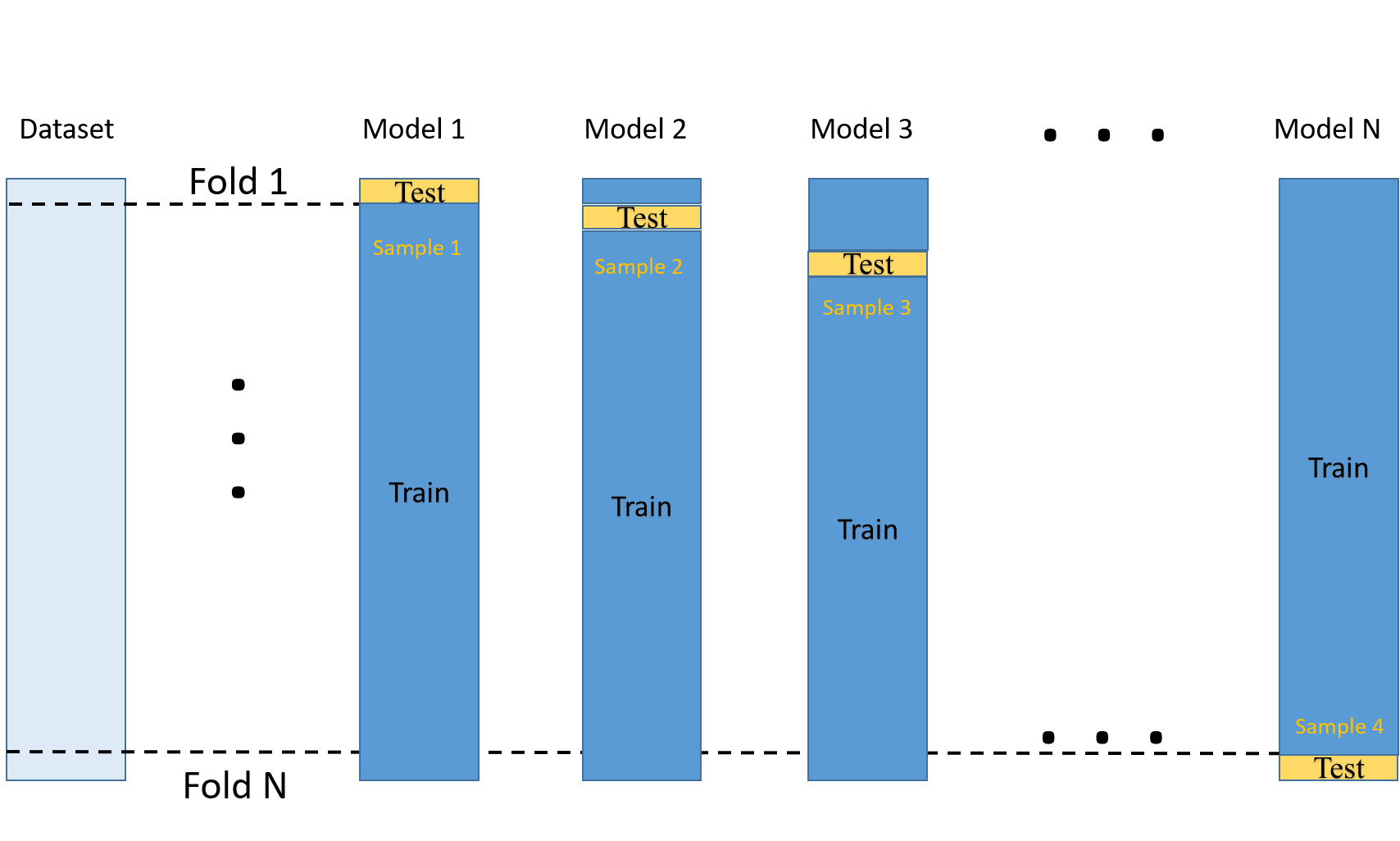
Leave-one-out cross-validation
The Scikit-learn documentation says that LeaveOneGroupOut is a cross-validation scheme which holds out the samples according to a third-party provided array of integer groups. This group information can be used to encode arbitrary domain specific pre-defined cross-validation folds.Each training set is thus constituted by all the samples except the ones related to a specific group The image below shows how the dataset is split.
Validation curves
Sometimes we want to evaluate the effect that an important parameter of a model has on the cross-validation scores. The useful function validation_curve makes it easy to run this type of experiment. This fucation will do threefold cross-validation by default but can be changed to different fold with the CV parameter. The other parameters are a classifier, parameter name, and set of parameter values, we want to sweep across.
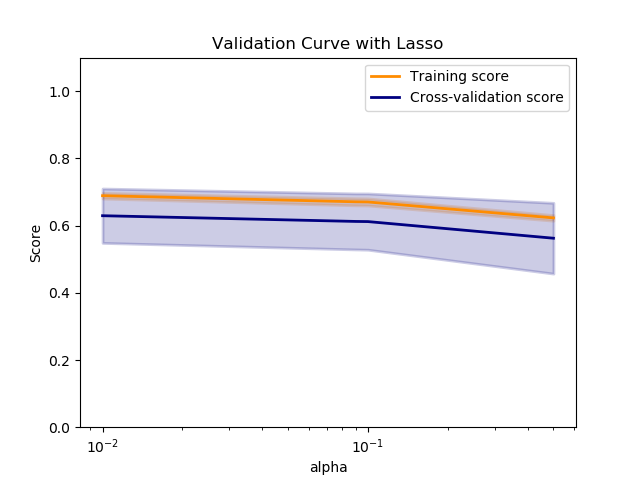
The below code shown here as an example will fit four Lasso Regression models with different alpha parameters and with five different folds. So each model will fit five different fold and a total of 20 train and test scores each is returned. The returned values is displayed in four-by-five arrays.
We can plot these results from validation curve as shown here to get an idea of how sensitive the performance of the model is to changes in the given parameter.The x axis corresponds to values of the parameter (here alpha) and the y axis gives the evaluation score
Before concluding let's remind that Cross Validation is used to evaluate the model and not learn or tune a new model.
I hope you liked this tutorial. You can find the complete code as a jupyter notebook on my github page. Useful resources to read:
If you have any question or feedback, please do reach out to me by commenting below.