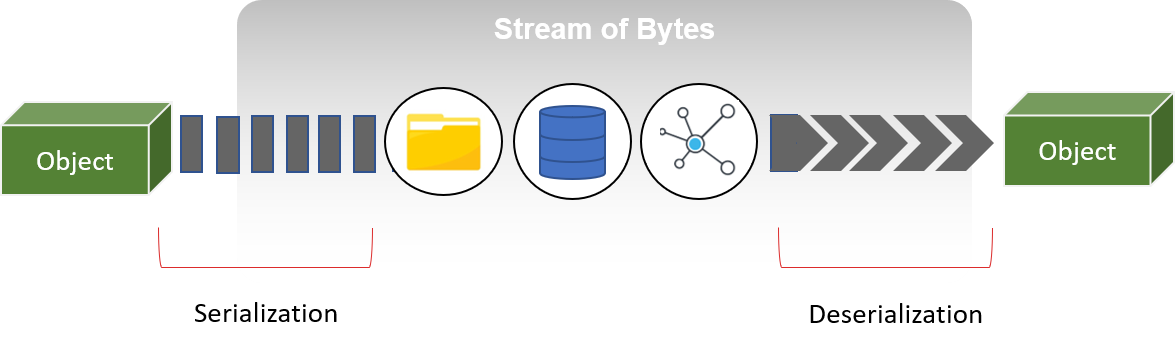
Serialization is the process of converting an object into a stream of bytes to store the object or tranfer over a network. Its main purpose is to save the state of an object in order to be able to recreate it when needed. The reverse process is called deserialization. There are various ways to achieve serialization/deserialization like JSON, XML, Avro or in Java using Serializable interface. This post is about Protocol Buffers which started gaining popularity in the recent years for its efficient serialization and deserialization.
1 Protocol Buffers
Protocol Buffers are developed by Google. It is an extensible serialization technique for the structured data. Once the structured data is defined, then source code can be generated to easily read and write the data using variety of languages. The main advantage of using protobuf is backaward and forward compatibility.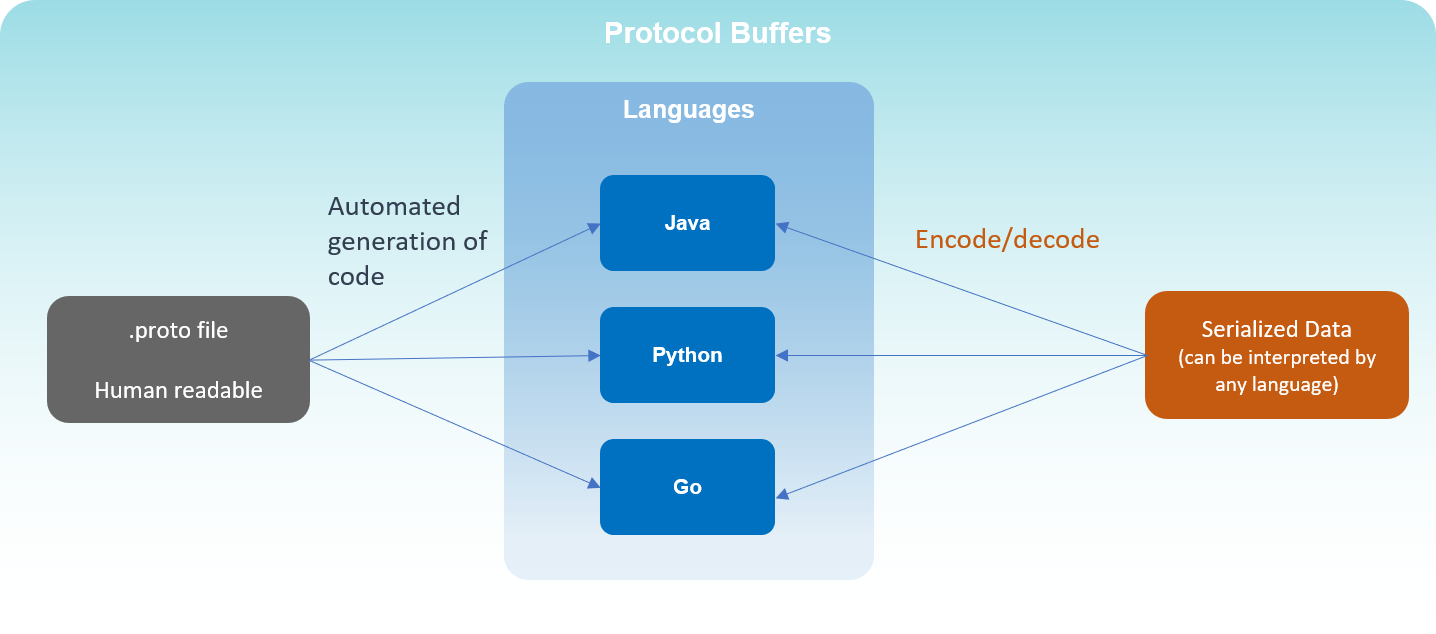 Specify the structured data that you want to serialize by defining protocol buffer message types in .proto specification file. Each protocol buffer message is a small logical record of information.
From the proto file, the protocol buffer compiler will generate a class that can be used in an application to serialize and deserialize.
Specify the structured data that you want to serialize by defining protocol buffer message types in .proto specification file. Each protocol buffer message is a small logical record of information.
From the proto file, the protocol buffer compiler will generate a class that can be used in an application to serialize and deserialize.
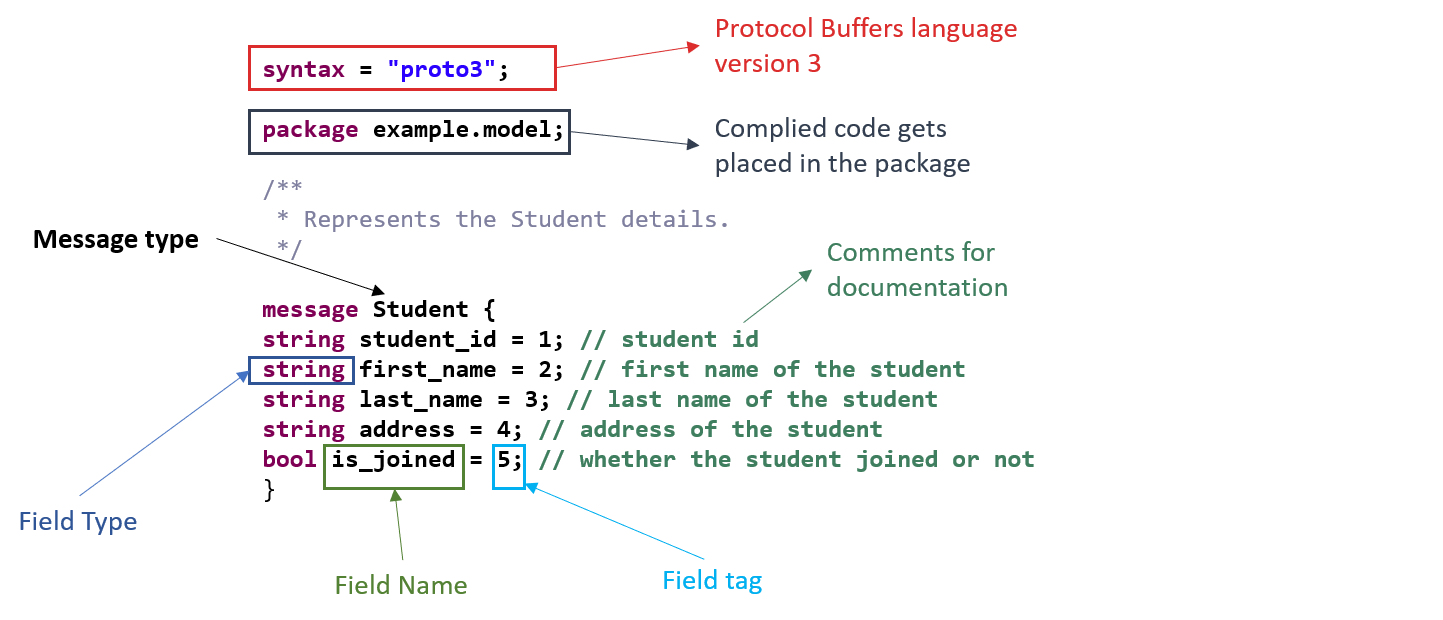
1.1 Basics: Defining the first message
1.1.1 Types
The complete list of message types in detail can be found here. The following are some of the types that can be used.
- Number : double,float, int32 ,int64, unit32 ..... are used as field type
- Boolean : 'bool' is used in the field type when you want a field with boolean type
- String : 'string' is used for string tyoe. A string must always contain UTF-8 encoded or 7 bit ASCII text
- Bytes : 'bytes' is used for any sequence of byte array.
Importing types
Types can be imported in a different .proto files or when you want to re-use the code and import other .proto files created by people
import "date.proto";
1.1.2 Tag
Tag is the most important element. The smallest being 1 and largest being 219 - 1 . We cannot use the numbers from 19000 to 19999 since they are reserved. Tags numbered from 1 to 15 use 1 byte in space and from 16 to 2047 use 2 bytes.
string first_name = 1;
string last_name = 2;
1.1.3 Repeated fields
The repeated fields are used to make a 'list' or an 'array'. The list can take any number (o or more) of elements.The opposite of repeated is singular.
repeated string numbers;
1.1.4 Default values
All fields will take a default value when not specified.
- bool: false
- number (int32): 0
- string: empty string
- bytes: empty bytes
- enum: first value
- repeated: empty list
1.1.5 Enum
You can use enum when you know all the values a field can take in advance. The first value of enum is the default value. It must start by the tag 0.
enum Eyecolor {
UNKNOWN_EYE_COLOR = 0;
EYE_GREEN = 1;
EYE_BROWN = 2;
};
1.1.6 Package
The protobuf compiler places the code at the package indicated. It prevents name conflicts between the messages.
package date;
1.2 Rules for Updating Protocol Buffers
- The numeric tags should not be changes for any existing fields
- New fields can be added and the old code will just ignore them.
- Likewise, if the old/new code reads unknown data, the default will take place.
- Fields can be removed as long as the tag number is not used again in the updated message typeYou may want to rename the field instead, perhaps adding the prefix "OBSOLETE_" or make the tag reserved, so that future users of the proto can't accidentally resuse the numner
- Default values should be used with car.
Defaults are tricky to deal with. They allow protobuf to easily evolve without breaking any existing or new codes. They also ensure the a field will always have a non null values. They are dangerous too because you cannot differentiate from a missing field or if a value equal to the default was set. The most important note is the default value shouldn’t have any meaning in the business.
1.2.1 Adding Fields
The tag number ensures the forward and the backward compatibility. After adding a new field, if it is sent to old, the old code will not know what the tag numbers corresponds to and the field will be ignored or dropped. This ensures backward compatibility. Oppositely, if we read the old data with the new code, the new field will not be found and the default value will be assumed (empty string, empty list etc...).
1.2.2 Renaming Fields
The field names can be changed freely. The tag number is the most important in protobuf.
1.2.3 Removing Fields
A field can be removed when it is not required anymore. If the old code doesn't find the field anymore, the default will be used. Oppositely, if we read the old data with the new code, the deleted dield will be just be dropped.
Removing Fields: Reserved Tags
When removing a field, you should always reserve the tag and the name. This prevents the tag to be re-used. This is necessary to prevent conflcits in the codebase
The alternatives is that insteas of removing a field it can be renamed to OBSOLETE_field_name. The downsode is that you may have to populate that field while your client gets upgraded to use the newer field that replaces it (which has a new tag).
1.2.4 Reserved Keywords
Tags and field names are reserved to prevent new fields from re using the tags. Tags and field names can't be mixed in the same reserved statment.
message Student{
reserved 2, 5 , 10 to 12;
reserved "name" , "mail";
}
Do not remove any reserved tags ever.
1.3 Advanced Types
1.3.1 Oneof
Oneof is used when you want to set oneof the fields. The field that is set will contain a value and rest of the fields will be null. Oneof fields cannot be repeated.
message Student{
int32 student_id = 1;
oneof language_course{
string lang_eng = 2;
string lang_fre = 3;
}
}
In the above example, you can either set lang_eng or lang_fre. I will create a separate post for a better understanding of oneof.
1.3.2 Maps
Maps are used to store key value pairs like in any other programming languages. A map cannot be repeated. The following is an example of map.
message Student{
int32 student_id = 1;
map<string,string> additional_info;
}
1.3.3 Timestamp
Protocol Buffers contain a set of well known types. One of the types is Timestamp. Its fields are seconds and nanoseconds. We have to explicity import the Timestamp type.
import "google/protobuf/timestamp.proto";
message Student{
google.protobuf.Timestamp last_updated = 1;;
}
1.3.4 Duration
It is another well known type. It represents the time span between two timestamps. It contains seconds and nanoseconds just like Timestamp.
import "google/protobuf/duration.proto";
message Student{
google.protobuf.Duration validity = 1;
}
1.4 Example
1.4.1 Defining the Protocol Buffers
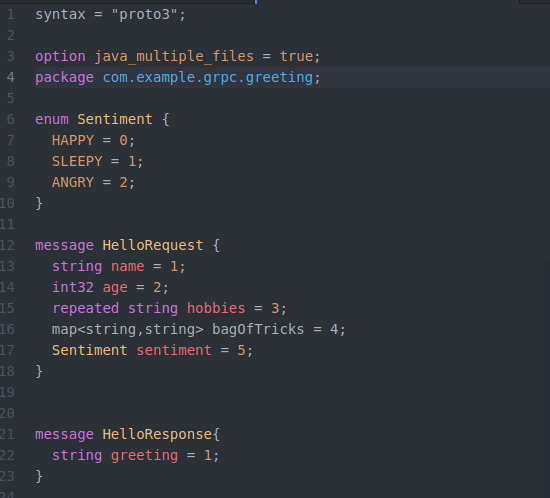
The following shows a simple .proto file which has two messages HelloRequest and HelloResponse.
1.4.2 Compiling the Protocol Buffers
The steps to compile are as follows
- Download the Protocol Compiler from here.
- Set the path to protoc or you can mention the path everytime you compile the code using --
proto_path=IMPORT_PATH - Go to .proto file folder and run the folowing command. we are using --java_out for Java files as output. Other options are --python_out,--cpp_out...
echo 'export PATH="$PATH":/home/user/Documents/softwares/protoc-3.7.1-linux-x86_64/bin' >> ~/.bashrc
protoc --java_out=../java greeting.proto
The github project for this example can be found here.
I have used the following references and sometimes used the same explanation. Do check the following resources for more understanding.
If you have any question or feedback, please do reach out to me by commenting below.